Frontier Open Source Speech Understanding Models
Voice was humanity's first interface. As digital systems become more capable, voice is returning as our most natural form of human-computer interaction. Voxtral is Mistral AI's frontier open source speech understanding models, providing open, affordable, and production-ready speech understanding for everyone.
Voice: The Original UI
Voice was humanity's first interface—long before writing or typing, it let us share ideas, coordinate work, and build relationships. As digital systems become more capable, voice is returning as our most natural form of human-computer interaction.
Yet today's systems remain limited—unreliable, proprietary, and too brittle for real-world use. Closing this gap demands tools with exceptional transcription, deep understanding, multilingual fluency, and open, flexible deployment.
We release the Voxtral models to accelerate this future. These state‑of‑the‑art speech understanding models are available in two sizes—a 24B variant for production-scale applications and a 3B variant for local and edge deployments. Both versions are released under the Apache 2.0 license, and are also available on our API.
Open, Affordable, and Production-Ready
Until recently, gaining truly usable speech intelligence in production meant choosing between two trade-offs: open-source ASR systems with high word error rates and limited semantic understanding, or closed, proprietary APIs that combine strong transcription with language understanding, but at significantly higher cost and with less control over deployment.
Voxtral bridges this gap. It offers state-of-the-art accuracy and native semantic understanding in the open, at less than half the price of comparable APIs. This makes high-quality speech intelligence accessible and controllable at scale.
50% Lower Cost
Voxtral API costs just $0.001 per minute, half the price of Whisper API while delivering superior performance.
Natively Multilingual
Automatic language detection and state-of-the-art performance in the world's most widely used languages, helping teams serve global audiences with a single system.
Open Source
Apache 2.0 licensed models available on Hugging Face. Deploy locally, customize, and build without vendor lock-in.
Built-in Q&A and Summarization
Supports asking questions directly about the audio content or generating structured summaries, without the need to chain separate ASR and language models.
Core Capabilities
Both Voxtral models go beyond simple transcription with capabilities that include:
Long-form Context
With a 32k token context length, Voxtral handles audios up to 30 minutes for transcription, or 40 minutes for understanding.
Built-in Q&A and Summarization
Supports asking questions directly about the audio content or generating structured summaries, without the need to chain separate ASR and language models.
Natively Multilingual
Automatic language detection and state-of-the-art performance in the world's most widely used languages (English, Spanish, French, Portuguese, Hindi, German, Dutch, Italian, to name a few).
Function-calling Straight from Voice
Enables direct triggering of backend functions, workflows, or API calls based on spoken user intents, turning voice interactions into actionable system commands without intermediate parsing steps.
Highly Capable at Text
Retains the text understanding capabilities of its language model backbone, Mistral Small 3.1.
Voxtral Models
Choose the perfect Voxtral model for your use case. From production-scale deployments to local development, Voxtral offers flexible solutions for every speech AI need.
Voxtral Small
ProductionVoxtral Mini
RecommendedPerformance Benchmarks
Voxtral achieves state-of-the-art results across multiple benchmarks, consistently outperforming leading speech recognition models in accuracy, multilingual support, and audio understanding.
Speech Transcription
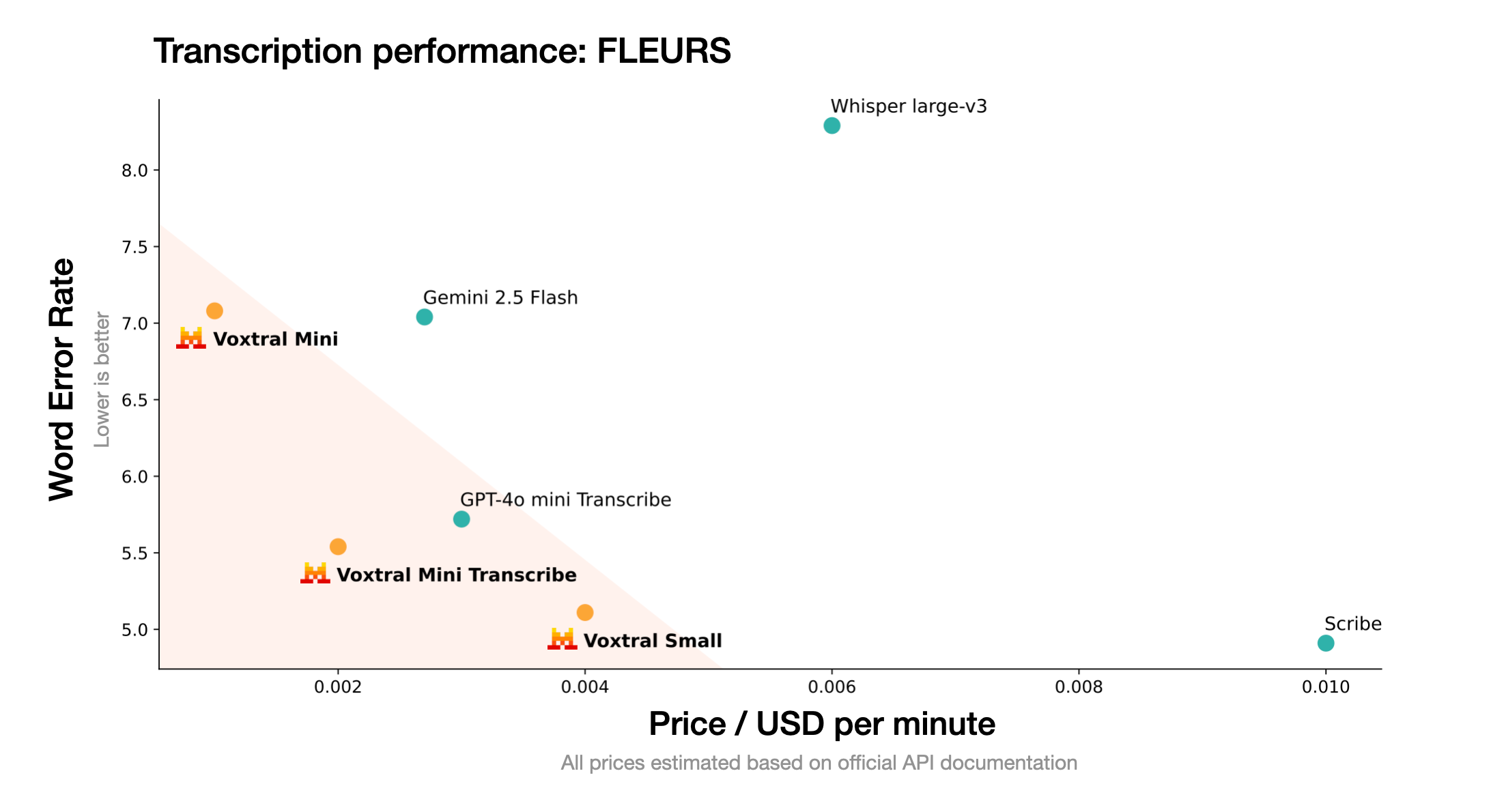
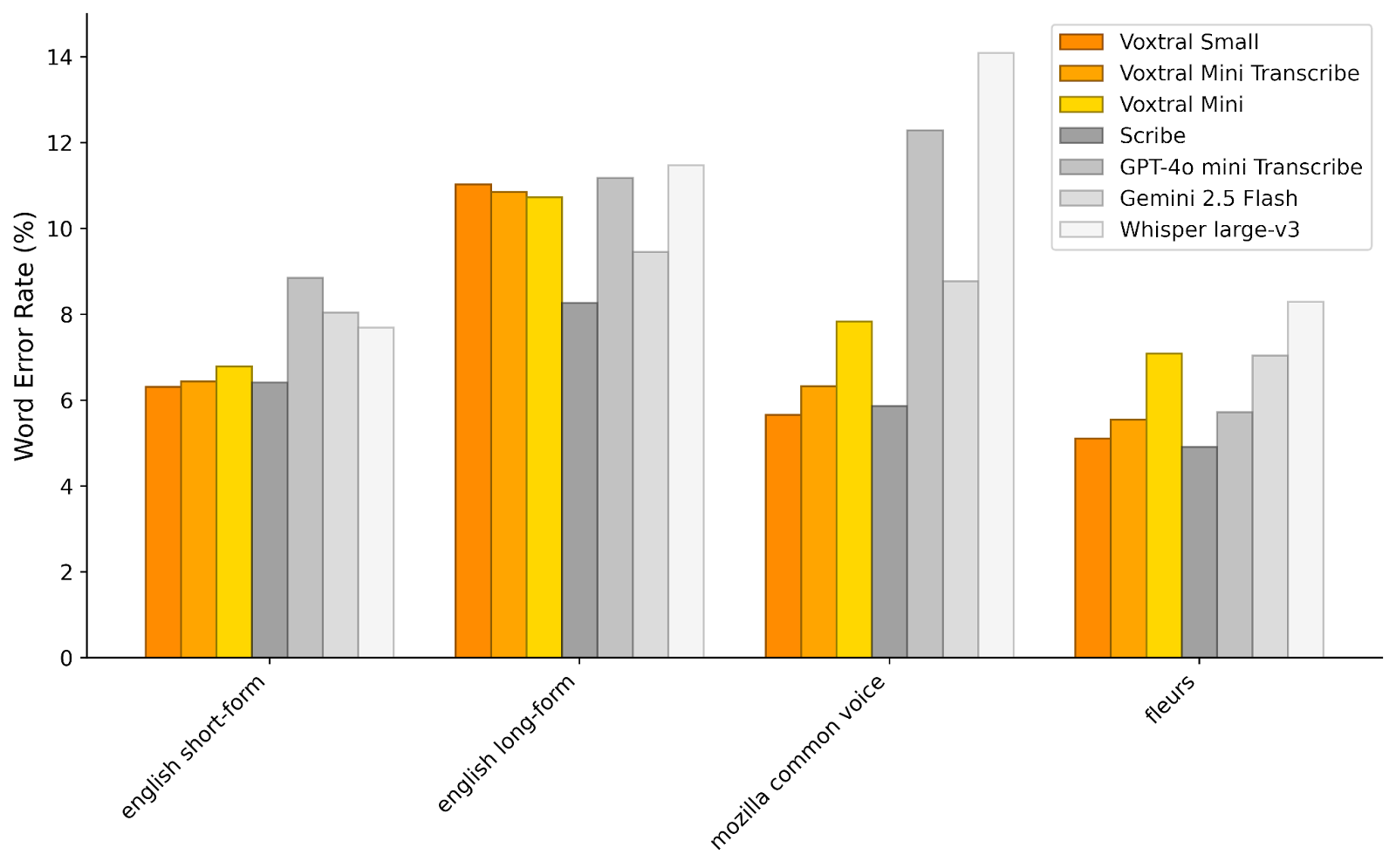
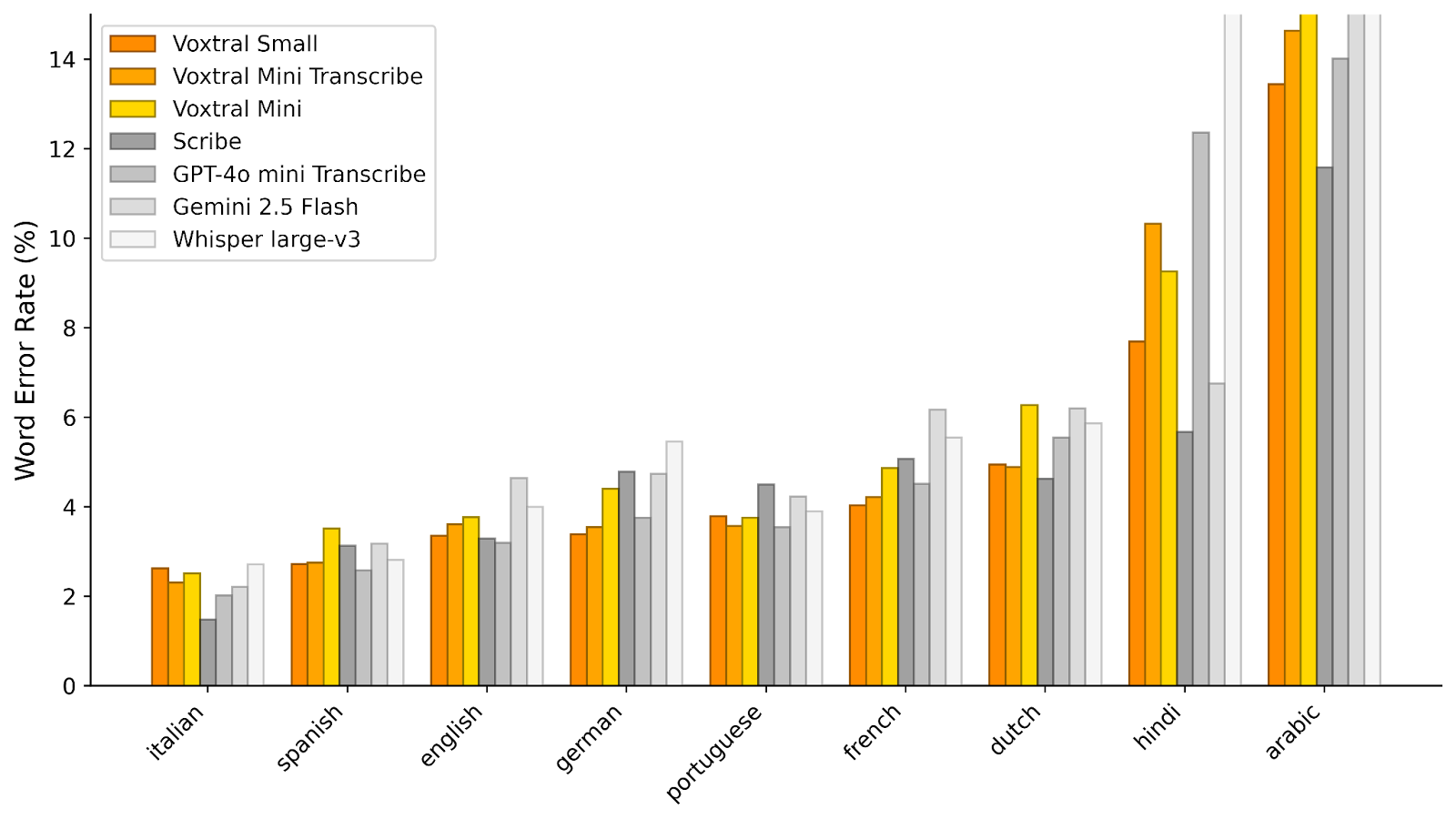
To assess Voxtral's transcription capabilities, we evaluate it on a range of English and multilingual benchmarks. For each task, we report the macro-average word error rate (lower is better) across languages. For English, we report a short-form (<30-seconds) and long-form (>30-seconds) average.
Voxtral comprehensively outperforms Whisper large-v3, the current leading open-source Speech Transcription model. It beats GPT-4o mini Transcribe and Gemini 2.5 Flash across all tasks, and achieves state-of-the-art results on English short-form and Mozilla Common Voice, surpassing ElevenLabs Scribe and demonstrating its strong multilingual capabilities.
Audio Understanding
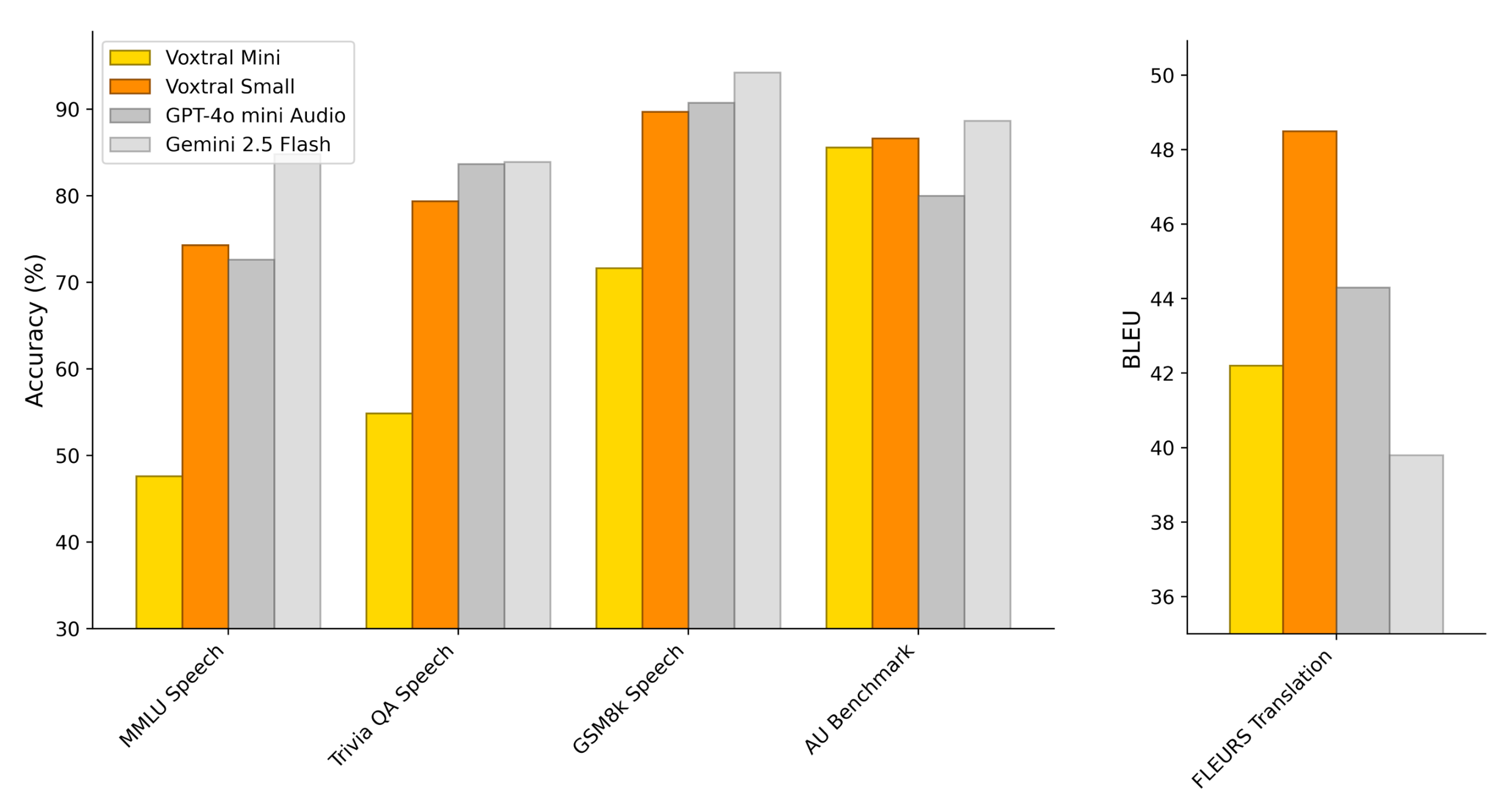
Voxtral Small and Mini are capable of answering questions directly from speech, or by providing an audio and a text-based prompt. To evaluate Audio Understanding capabilities, we create speech-synthesized versions of three common Text Understanding tasks. We also evaluate the models on an in-house Audio Understanding (AU) Benchmark, where the model is tasked with answering challenging questions on 40 long-form audio examples.
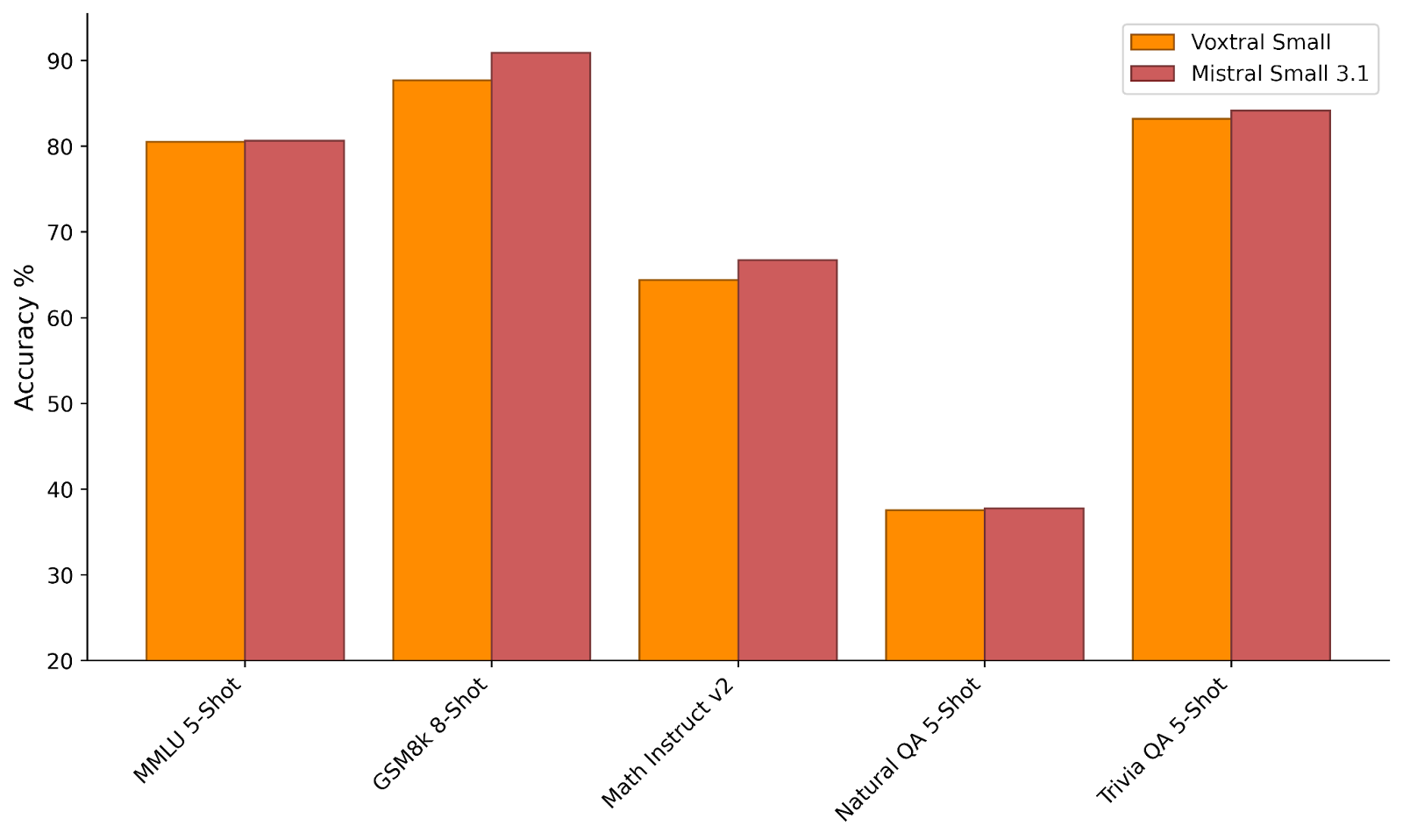
Text Capabilities
Voxtral retains the text capabilities of its Language-Model backbone, enabling it to be used as a drop-in replacement for Ministral and Mistral Small 3.1 respectively.
Use Cases
These capabilities make the Voxtral models ideal for real-world interactions and downstream actions, such as summaries, answers, analysis, and insights. For cost-sensitive use-cases, Voxtral Mini Transcribe outperforms OpenAI Whisper for less than half the price. For premium use cases, Voxtral Small matches the performance of ElevenLabs Scribe, also for less than half the price.
Voice Agents & Chatbots
End-to-end speech-to-action workflows with a single model. Voxtral enables seamless voice interaction without complex chaining.
Customer Support Analytics
Live transcription and semantic tagging of support calls. Voxtral provides real-time insights and automated call analysis.
Podcast & Lecture Summarization
Generate Q&A and summaries from long audio content. Voxtral's 32k context window handles extended conversations effortlessly.
Accessibility Tools
Low-cost, on-device captioning and voice control. Voxtral Mini enables local deployment for privacy-sensitive applications.
Developer Tooling
Open weights enable custom fine-tuning and local prototypes. Build without vendor lock-in using standard ML tooling.
Multilingual Applications
Automatic language detection and superior performance across 8+ languages. Perfect for global applications and content.
Try it for Free
Whether you're prototyping on a laptop, running private workloads on-premises, or scaling to production in the cloud, getting started is straightforward.